가상환경 설정 및 MVP 구현Dataset과 Vector DB 구현Dataset 확보- Vector DB 구현
- Embedding & Searching 구현
- Generation 구현
이전의 포스트에 이어 이제는 Faiss를 활용해 Vector Store를 구현했다. 그리고 여기서 먼저 말하고 싶은게 있다.
절대로 ChatGPT를 써서는 안된다. ChatGPT의 경우 구현에 대한 클루와 인사이트를 줄 수 있으나 디테일한 부분에 있어서는 공식문서가 더 확실하다. 그리고 ChatGPT가 정확하다면 모델을 파인튜닝하거나 지금과 같이 RAG 방식을 구현한다는게 의미가 없을 것이다.
FAISS의 구체적인 부분에 있어 아래의 포스트를 참고하면 좋다.
2.도대체 FAISS 그리고 Vector Store는 뭘까?
3.도대체 Embedding Model과 Token은 뭘까?
먼저 LangChain을 통한 FAISS Vector Store 생성을 위해서 먼저 FAISS가 어떻게 구성 됐는지 보자.
index = faiss.IndexFlatL2(len(OpenAIEmbeddings().embed_query("hello world")))
vector_store = FAISS(
embedding_function=OpenAIEmbeddings(),
index=index,
docstore= InMemoryDocstore(),
index_to_docstore_id={}
)- embedding_function: 임베딩 모델을 지정해준다.
- index: 공식 문서에는 Any라고 하고 무책임하게 Index to use라고 한다. 그런데 여기서 말하는 Index는 Embedding 된 후의 데이터 구조라고 생각하면된다. 그래서 임베딩 모델을 선정한 후 임베딩모델로 간단한 단어의 임베딩을 진행한 뒤에 그 결과의 구조를 집어 넣으면 된다. Dimension Length라고도 생각해도 된다.
- docstore: Docstore로 저장된 정보에 대한 접근 정보라고 생각하면된다 그래서 아래의 index_to_docstore_id와 연관되어 있다. 간단하게 InMemoryDocstore로 지정해도 된다.
- index_to_docstore_id: index와 Docstore를 연결하는 부분이라고 생각하면된다. 아직 어떠한 Document도 담지 않았으니 빈값으로 넣어도 된다.
그래서 FAISS를 Vector Store로 사용하기 위해서는 아래의 순서로 진행하면된다.
- Embedding Model 선정
- Json을 Document로 전환 및 저장
- Document
- ids
- Vector Store에 저장된 내용 로컬에 저장
생각보다 간단해 보인다. 물론 저안에서 돌아가는 것을 보게 된다면 LangChain의 소중함을 느끼게 될것이다.
그래서 바로 구현을 진행하면 아래와 같다.(Vector Store를 구현하고 Index로 전환하는 과정에 필요한 필수 패키지는 아래의 Github 주소로 넘어가면 확인 할 수 있다.)
개발 환경은 Colab에서 진행 됐다는 점을 참고해야 한다.
Embedding Model 선정
import os
os.environ['OPENAI_API_KEY'] = userdata.get('openAI')
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
가장 많이 쓰이는 OpenAI의 임베딩 모델을 사용했다. 참고로 외부 임베딩 모델을 사용할 경우 이게 천하무적이 아니라는 사실을 간과해서는 안된다. 꼭 임베딩 모델의 성능과 제약에 대해서 확인해 봐야 한다.
Json 데이터를 Document로 전환
JSON을 이미 불러왔다는 가정하에 진행하겠다. 그러면 Document는 뭘까? Langchain 공식문서에 따르면 Document는 기본적으로 정보를 Langchain을 통해 Vector Store에 저장하기 위한 형식이라고 생각하면 된다.
기본적인 사용 형태는 아래와 같다.
from langchain_core.documents import Document
document = Document(
# String
page_content="Hello, world!",
# Dictionary
metadata={"source": "https://example.com"}
)
위에서 알 수 있듯이 Document로 전환하기 위해서는 저장된 Json을 먼저 String으로 전환해주어야 한다.
metadata의 경우 page_content와 연관된 필터와 같은 역할을 할 수 있는 정보다. 그렇기 때문에 우리가 추가하려고 하는 모든 데이터에 공통적으로 포함되고 구분할 수 있는 역할을 할 수 있는 정보여야한다.
그래서 이번 프로젝트에 사용되는 데이터의 형태가 아래와 같아 먼저 아래의 json을 String으로 전환하였고 json의 필드를 구분하기 위하여 [SEP]이라는 부분을 넣어 주었다.
for row in data:
text = f"{row['ad_gu']} [SEP] {row['ad_dong']} [SEP] {row['address']} [SEP] {row['location']} [SEP] " \
f"{row['description']} [SEP] {row['rating']} [SEP] {row['share_link']} [SEP] " \
f"{' '.join(row['reviews'])} [SEP] {row['info']}"
clean_text = text.replace("\n", " ")
documents.append(Document(page_content=clean_text))
uuids = [str(uuid4()) for _ in range(len(documents))]
동시에 documets를 전환하며 uuid4를 활용해서 ID 또한 만들어 줬다.
여기서 중요한 점은 무조건 두 리스트의 순서가 똑같아야한다.
Document를 FAISS Vector에 저장 및 로컬 환경에 저장
그리고 마지막으로 FAISS Vector Store 객체를 만들고 생성된 documents와 uuids 리스트를 저장하면 된다. 그리고 Vector Store에 저장될 때 까지 놀다 와도 된다. Colab을 통해서 GPU를 사용 하면 빨라지기는 하지만 아래의 문제 상황을 참고하여 잘 구성해야한다.
그리고 저장된 내용을 바로 local에 저장한다.
import faiss
from langchain_community.docstore.in_memory import InMemoryDocstore
from langchain_community.vectorstores import FAISS
index_cpu = faiss.IndexFlatL2(len(embeddings.embed_query(documents[0].page_content)))
vector_store = FAISS(
embedding_function=embeddings,
index=index_cpu,
docstore=InMemoryDocstore(),
index_to_docstore_id={},
)
vector_store.add_documents(documents=documents, ids=uuids)
# 로컬 저장환경까지의 경로다
vector_store.save_local(faiss_index_path)
이 과정을 통틀어 Vector DB 구현이 아니라 정확히는 Data Ingestion이라고 한다.
데이터 수집하고 수집된 데이터를 Vector Store로 저장하기 위해 전환하고 저장 하는 과정이다.
물론 여기까지 오면서 문제상황이 몇가지 발생했다.
- TPM 문제
- FAISS가 최선일까? Pinecone과 같은 다른 방식들도 있는데?
- FAISS를 사용함에 있어 가장 적합한 형태의 Document는 뭘까?
TPM 문제
Token Per Minute의 약자로 Index를 생성함에 있어 저번에 설명하였듯이 Tokenization을 진행하고 Embedding을 진행한다.
그런데 여기서 문제는 Embedding 모델별로 처리할 수 있는 Token의 개수가 지정 돼있다. 이번에 사용하게된 text-embedding-3-large의 경우 1분에 100만개다. 엄청 많아 보이지만 실제로 Document 하나가 내용이 많거나 여러개의 Document들을 연속적으로 임베딩하게 되면 많은 양이라고 할 수 없기 때문에 문제가 생길 수 있다. 특히, 이런 재약들은 외부에서 모델을 가져와 사용할 때 조심해야한다. 또한 나에게 발생한 이 문제도 기존의 Index를 업데이트 하는 과정에 있어서 발생하게 됐다.
그래서 위와 같은 문제를 해결하기 위해 총 2가지의 해결 방식이 떠올랐다.
- 수동적으로 Document 임베딩 과정을 늦추는 법
- 이 문제에서는 결국 수동적으로 Document의 임베딩에 sleep을 걸어 아래와 같이 해결했다.
- Document 임베딩 과정을 처음부터 다시하는게 아닌 추가하는 형식으로 전환하는것
- 이부분에 있어 FAISS가 최선인가? 하는 생각이 들었다. 아래에 구체적으로 작성하겠다.
먼저 documents와 uuids 나눠서 저장과정에 강제로 sleep을 준 방식이다. 특히, append와 같이 저장이 되기 때문에 이 방법이 가장 효율 적으로 보였다.
그런데 문제는 기존의 Vector Store를 기반으로 update를 진행할 경우 기존의 데이터에 대한 중복이슈를 uuids로 인해 바로 에러를 일으킨다.
그런점을 참고해서 Data Ingestion을 진행했다.
from time import sleep
sliced_documents = [documents[i:i+int(len(documents)/100)] for i in range(0, len(documents), int(len(documents)/100))]
sliced_uuids = [uuids[i:i+int(len(uuids)/100)] for i in range(0, len(uuids), int(len(uuids)/100))]
for index in range(len(sliced_documents)):
vector_store.add_documents(documents=sliced_documents[index], ids=sliced_uuids[index])
print(f"{round((index+1)/len(sliced_documents)*100,2)}% Done")
sleep(5)
그 다음으로는 처음부터 진행하는게 아닌 Update 혹은 추가하는 방식이었는데 여기서 FAISS에 문제가 있었다. 왜냐면 FAISS의 경우 ids를 지정해줘야한다. 하지 않는 다면 vector_store에서의 사용에 제약이 생길 수 있다. 물론 여기서 add_documents 함수의 반환된 id list를 사용할 수 있으나 문서에서 추천하는 방식은 아닌거 같다.
그렇다 보니 정보가 계속 크롤링되는 상황에서 FAISS가 유연하지 못하다는 생각이 들었다. 그래서 Pinecone과 같은 외부 DB를 고민하기 시작했다. FAISS에서의 id 지정 파트가 없었고 외부 DB였기에 쉽게 접근할 수 있는것도 장점이었고 심지어 사용하기도 편했다.
하지만, 내가 현재 불편을 느끼는 부분들은 유료 버전에서만 사용이 가능하다. 그래서 결국 FAISS를 사용하기로 유지하고 대신 Update할 수 있는 방식을 최대한 사용했다.
가장 적합한 형태의 Document
FAISS의 특정할 수 있겠지만, 이번의 경우 Json의 filed(혹은 column) 이름에 맞춰 Document의 값을 넣어 놨다.
하지만 이런게 최선이라는 생각이 들지는 않았다. 왜냐면 여기서 Metadata도 뽑아 내지 못했고 content의 경우도 모델이 최적으로 이해할 수 있게 구성하지 못했다는 생각이 들었다. 그래서 물론 서비스의 의도, RAG에서 사용되야 하는 정보의 특성에 따라 달라지겠지만 결국에 서비스에 맞는 Document구성은 어떻게 될까? 라는 궁금증을 얻게 됐다. 그래서 이번의 경우에는 결국 구현이 급해 [SEP]으로 나눴지만 다음에는 프로젝트 혹은 기회에서 서비스의 의도 그리고 확보된 데이터의 특성에 맞춰 Document을 구성해야겠다는 생각이 들었다.
이렇게 결국에는 MVP RAG에서 추가적인 Vector Store 까지 연결 될 수 있었다. 그래서 아래와 같은 현재까지 구현이 완료 됐다.
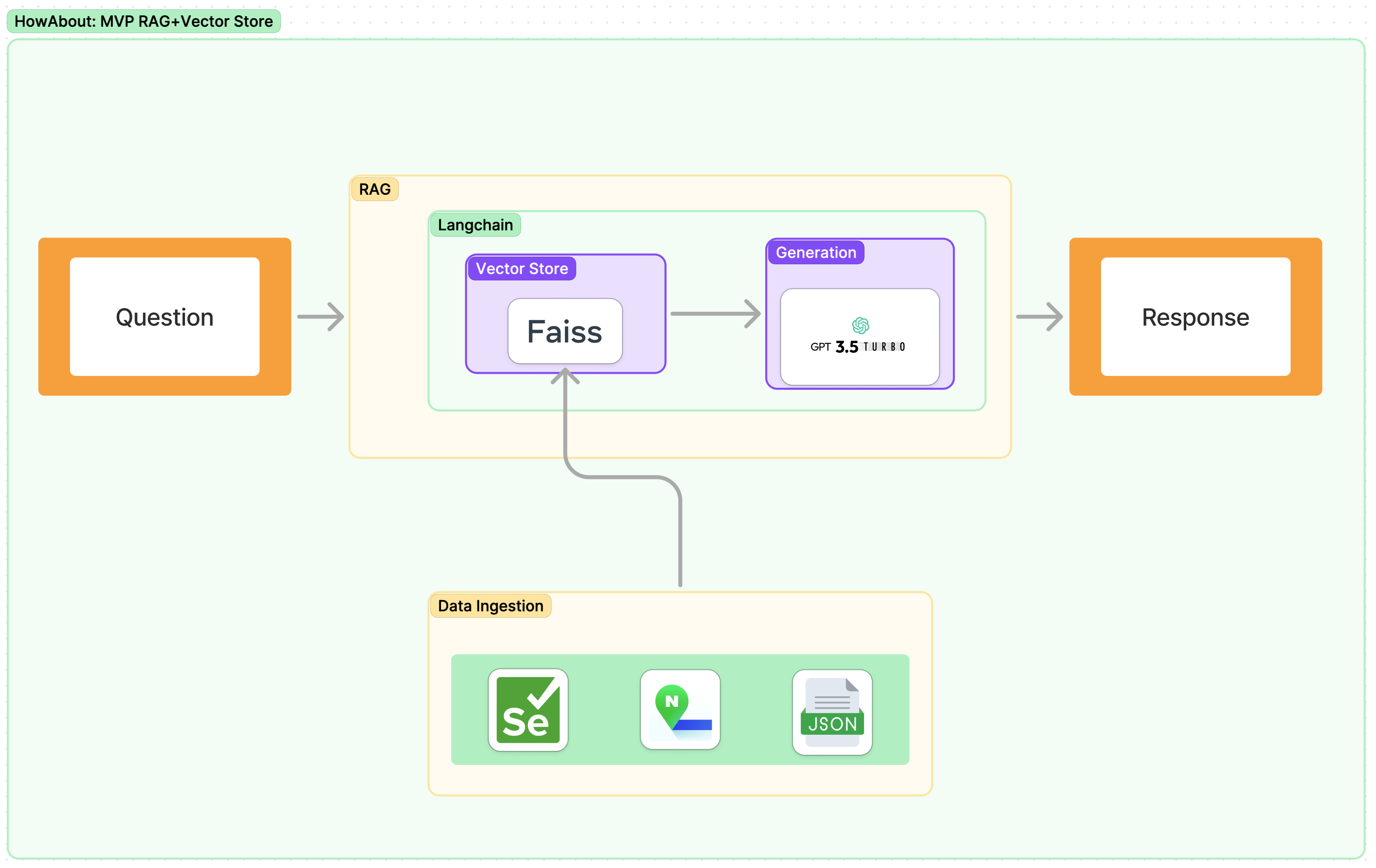
구체적인 코드를 보고 싶다면 아래의 깃헙 저장소에서 참고 하면 된다.
RAG Vector Store with LangChain
RAG/rag-practice/rag-vector-db-langchain/rag_vec_db_langchain.ipynb at main · jwywoo/RAG
1. RAG Practice. Contribute to jwywoo/RAG development by creating an account on GitHub.
github.com
그럼 다음으로 만들어진 Vector Store에서 좀 더 정확한 정보를 가져오기 위한 Embedding과 Searching에 대해 정리해 보았다.
RAG 구현 Step-by-Step Embedding & Searching
RAG 구현 Step-by-Step Embedding & Searching: Query Translation
RAG 구현 Step-by-Step: Intro가상환경 설정 및 MVP 구현Dataset과 Vector DB 구현Dataset 확보Vector DB 구현Embedding & Searching 구현Generation 구현위의 그림은 LangChain에서 RAG를 필요에 맞춰 수정할 수 있는 부분을
youcanbeable.tistory.com
참고 자료
'AI > Gen AI' 카테고리의 다른 글
| RAG 구현 Step-by-Step: Generation 및 API 전환 (8) | 2024.09.24 |
|---|---|
| RAG 구현 Step-by-Step Embedding & Searching: Query Translation (2) | 2024.09.20 |
| RAG 구현 Step-by-Step Vector DB 구현 - 1: Implementation Outline (1) | 2024.09.16 |
| RAG 구현 Step-by-Step Dataset 확보: Selenium을 활용한 Crawler (3) | 2024.09.02 |
| RAG 구현 Step-by-Step Dataset 확보 (1) | 2024.08.28 |